前言
最近看到一篇发表在Health promotion international上的论文Japanese anti-versus pro-influenza vaccination websites a text-mining analysis,作者对日本疫苗是“亲”还是“反”的两类网页的文本数据进行挖掘与分析,是一篇可参考学习其研究过程的文本挖掘论文,给我们展现了文本挖掘在公共卫生研究中的应用。
研究设计
首先,在数据获取方面。作者通过搜索引擎,用不同的检索方式(如疫苗&接受/不接受;如疫苗&有效/无效;如疫苗&有益/无益;如疫苗&效果/副作用),检索搜索引擎(Google (www.google.co.jp) and Yahoo! Japan (www.yahoo.co.jp))。然后, 每个检索式,获取前100个检索内容。人为剔除重复项,布告栏系统、视频、Twitter、Wikipedia、论流感疫苗接种地点/费用等内容的网页。最后共获取到334个网站(网页)。
其次,内容划分。一是根据其主张被分类为“专业”,“反对”或“中立”。二是根据作者身份被分类为“卫生专业人员”,“大众媒体”或“外行”: 当网页由医师,护士,药剂师或研究人员撰写的,或者如果它们出现在制药公司,研究中心,医院或市政当局的网站上,就是“卫生专业人员”;出现在报纸,杂志或新闻网站上的,归为“大众媒体”;其他作者,或未明确是卫生领域作者的,归为“外行”。
最后,过程编码。作者通过结合经常出现的术语逻辑运算符来创建编码规则,调查网页中经常出现的内容。总术语(terms )数量为218,145,剔除笼统术语(例如“ this”,“ it”,“ think”)后,得到前100个高频术语(作者用词频和 tf-idf scores 两项指标来确认前100的,虽然顺序有变化,但100个词的内容未变)。随后,作者使用层次聚类分析方法(hierarchical cluster analysis (Ward’s method)),并且,作者对术语进行了共现分析,Jaccard相似系数确定共现关系的程度;第一作者以1个月的间隔将这些分析过程重复两次,以确保一致性。最后将这100个高频词聚类为13类,得到13个内容主题。计算单位是段落Paragraphs,就是把所有网页中包含的各个段落,把它们贴上13个主题的分类label,如下所示:

分析过程
首先,作者用卡巴统计量(kappa statistic)来确认interrater 的一致性。用卡方检验,判断编码段落(code-fitted paragraphs)在“亲疫苗”于“反疫苗”网站中分步的差异性。
其次,作者发现,不同主体“亲”还是“反”的两类网页的分类分布差异很大,情况如下:
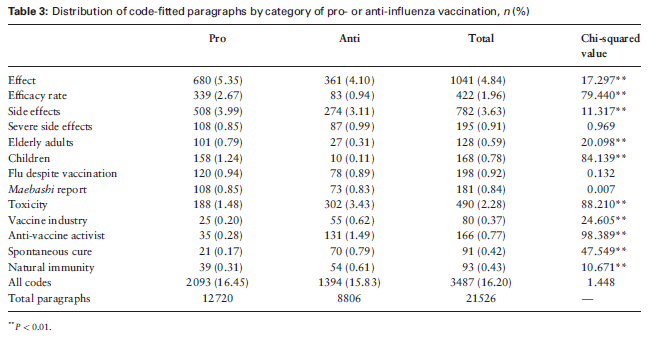
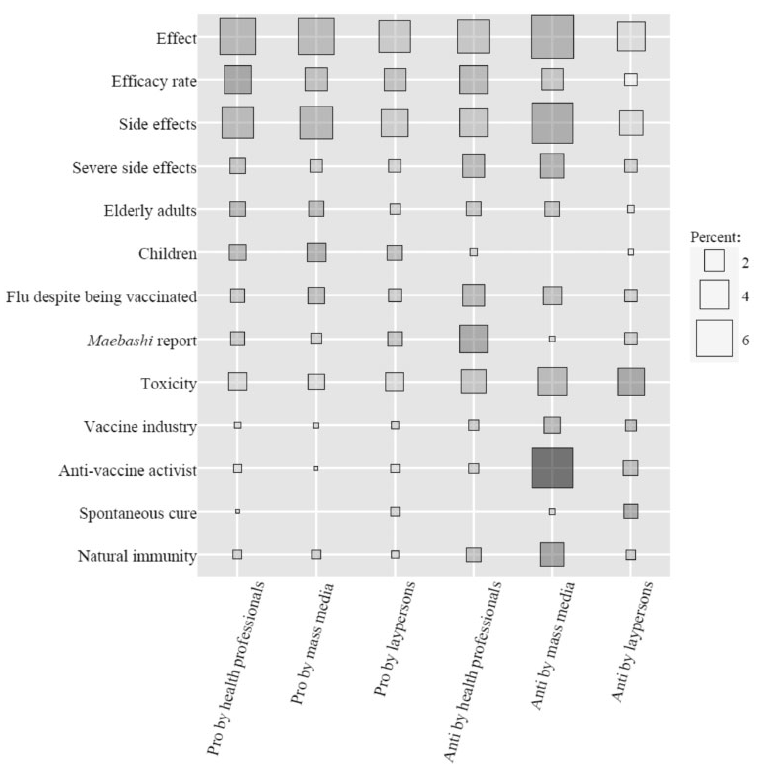
最后,作者也发现,不同作者群体,对13个不同主题的讨论深度是不一致的:正方形大小表示出现频率:正方形越大,该主题编码段落出现频率越高。 正方形阴影表示与其他作者相比(皮尔逊残差)的主题出现概率:正方形颜色越深,表明与其他类别相比,这类作者涉及这一主题的编码段落越多。例如,可以看到,大众媒体在“反”疫苗网站上非常喜欢提及“反疫苗激进主义者”的有关内容。
讨论与结论
根据得到的分析结果,可以发现,“反”疫苗的网站大约占据三分之一的数量,其中,大多数“反”疫苗网站的内容都是“外行”撰写的。还有,日本“反疫苗”的网页有很多轰动性的话题(例如疫苗毒性和副作用),而”亲疫苗”的网页倾向于讨论其科学性。这些发现可以结合已有的研究成果,也可以贴合现实实际。根据大量社交媒体的文本挖掘,可以更科学地讨论如何通过网页对疫苗进行推广活动的可能性,如何应对“反疫苗”网站的策略。
